22 декабря 2015
31 января 2011
8
Веб-разработка не против SEO: какими могут быть URL`ы в вашем следующем проекте
Важную роль в продвижении приобрели поведенческие факторы. Это отлично, потому что теперь на всех этапах создания и обслуживания сайта появилась общая цель: сделать сайт полезным и доступным для посетителя. Стремиться к этому следует при проектировании, дизайне, разработке и продвижении сайта. И, похоже, настали те времена, когда разработчики с маркетологами обязаны подружиться.
Однако, и прежде любой веб-разработчик в рамках своего этапа работ над сайтом — мог и может сделать много полезного для SEO. В этой статье поговорим о безопасных (с точки зрения поисковых лицензий) манипуляциях над URL, полезных для поисковой оптимизации и удобства пользования.
Эффективная контекстная реклама в Google, Yandex от компании Web-Promo.
Большинство современных веб-фреймворков используют URL (или, по крайней мере, его часть) как основной параметр для роутинга запроса от посетителя к нужному обработчику. Адреса страниц, к счастью, принято реврайтить, исключая непосредственные GET-параметры и превращая их в часть пути. То есть вместо классического, положим, /pub.php?id=120 уже почти везде используются более аккуратные варианты вроде: /pub/120.
Красивые адреса для людей и уникальный контент для поисковых машин
URL`ы с параметрами такие неопрятные, что популярный в наших краях браузер Opera 11 уже занимается их принудительным сокращением (показывая, впрочем, полный адрес по клику):
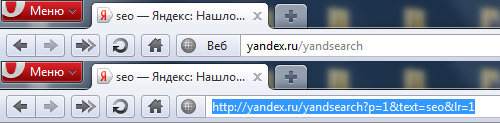
Однако, с точки зрения поисковых систем, в GET-параметрах нет ничего криминального. Лишь бы в адресе не болтался изменяющийся идентификатор сессии или иной хвост, выводящий ту же страницу, но в версии для печати. Проблемы дублирования контента из-за мусора в адресе по версии Яндекса можно побороть с помощью директивы Clean-Param в файле robots.txt, только вот паук Google названную директиву не понимает.
Для живых посетителей требуются более осмысленные «человеко-понятные» адреса страниц (их также называют: ЧПУ, SEF URLs, Clean URLs). Разработчики часто использует готовые модули или создают функционал для того, чтобы позволить администратору сайта добавлять к техническому адресу страницы (/articles/120) ещё и человек-понятный синоним (например: /winter-vacations.html). Ход в правильном направлении, но дополнительно следует позаботиться о следующих условиях:
- С технического адреса на человеко-понятный (если он задан) должен автоматически устанавливаться постоянный (301-й) редирект.
- В head-блоке страницы желательно указать её постоянный человеко-понятный адрес (например: <link rel="canonical" href="http://example.com/winter-vacations.html" />), после чего, понятное дело, адрес не следует изменять. Вообще, изменение адреса после того, как страница попала в индекс поисковиков лучше запретить технически (индексацию отслеживать ни так сложно, но ещё проще запретить правку адреса, например, спустя сутки после создания страницы).
- Если у страницы есть двойник с человеко-понятным адресом, то в версию по техническому адресу можно автоматически добавлять <meta name="robots" content="noindex, nofollow"> с упомянутой выше ссылкой на постоянной адрес страницы и редиректом.
- Пространство технических адресов желательно закрыть от индексации в файле robots.txt (например, Disallow: /pub), но, конечно, последнее справедливо только при условии, что администратор сайта гарантированно укажет человеко-понятные адреса для всех страниц.
- Технические адреса не должны попадать в XML-карту сайта.
- Технические адреса не должны фигурировать во внутренних ссылках (с других страниц того же сайта на страницу, у которой уже есть человеко-понятный адрес). В идеале, нужно добавить обработчик при сохранении контента в бэк-энде, отыскивающий все внутренние ссылки и автоматический заменяющий технические адреса на человеко-понятные.
Навигационные возможности адресов страниц
Сравним http://example.com/winter-vacations.html и http://example.com/articles/2011/winter-vacations.html. Не смотря на то, что второй URL-длиннее, он гораздо информативней и как бы намекает посетителю на то, где можно посмотреть архив статей за 2011-ый год (http://example.com/articles/2011/) или вообще все имеющиеся статьи (http://example.com/articles/).
Для Firefox даже существуют расширения, которые позволяют буквально кликать по фрагментам адреса, превращая вышеописанные догадки пользователя во внутренний переход по сайту, хотя, конечно, подобные расширения встречаются преимущественно у продвинутых гиков. На скриншоте эдд-он Locationbar²:
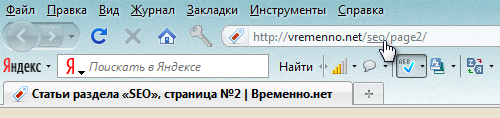
Chrome контрастно выделяет из всего адреса домен, но даже по нему кликнуть не даёт. Может для других браузеров уже есть похожие расширения? Если они вам известны, пожалуйста, расскажите о них в комментариях.
Не только для посетителей
Деление сайта на подразделы на уровне адресов поможет маркетологам и при анализе аудитории. Например, на скриншоте ниже представлены данные из Яндекс.Метрики (как видите, они группируются на основе адресов):
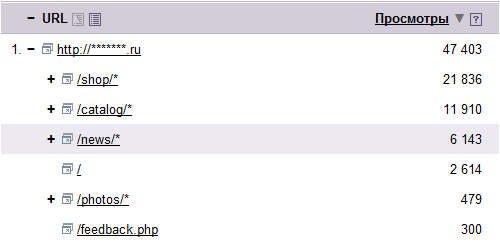
Связь адресов страниц с ранжированием
Вложенность страницы определяется всё равно на основе кратчайшего пути по ссылкам. То есть если на страницу http://example.com/articles/2011/winter-vacations.html будет установлена прямая ссылка с главной страницы, то она окажется на первом уровне вложенности (если главная — это нулевой), не смотря на свой адрес.
Эксперименты годичной давности показывают, что на тот момент имелась корреляция между ранжированием страницы по определенному запросу и адресом этой страницы, но только в достаточно узких областях, а именно в тех случаях, когда запрос и URL содержали упоминание оригинального (англоязычного) названия того или иного бренда. При прочих равных страница с релевантным адресом ранжировалась в Яндексе немного выше. Интернет-магазинам это следует учесть обязательно.
URL не входит в число ключевых факторов при ранжировании, сам по себе правильный адрес не поднимет страницу в топ. Но при нынешнем многообразии факторов ценен каждый положительный вклад. Согласны?
Кроме того, правильный URL по достоинству могут оценить ассесоры и посетители, подтянув вашему сайту поведенческие факторы.
Кириллические URL`ы
В настоящий момент Яндекс уверенно понимает кириллические URL`ы (не только домены). Заинтересовавшимся рекомендую ознакомиться с операторами языка запросов ~~ и inurl для проведения собственных экспериментов.
Более того, Яндекс понимает и транслит. Взгляните на некоторые результаты выдачи по запросу «невский»:
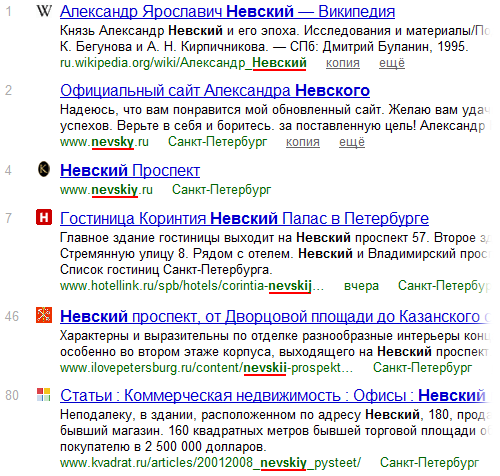
Google в этом же плане ведёт себя скромнее: по запросу «невский» он выделяет в адресах только вхождение «nevskiy», но игнорирует, например, «nevsky» и даже «Невский» в кириллическом адресе (последнее — очень странно). Однако, с выводами торопиться не стоит: если Google не выделил жирным вхождения запроса в URL— это совсем не значит, что он их не умеет интерпретировать для каких-то внутренних нужд.
Промежуточные итоги
Если разработчики и администраторы будущего сайта не испытывают какой-то особой эйфории по поводу кириллических доменов, то я бы рекомендовал строить традиционные URL`ы в транслите, в качестве разделителя между словами используя дефис.
Компоненты адреса, разделённые слэшами, по возможности, должны поддерживать парадигму директорий в файловой системе и помогать пользователю понять в каком разделе располагается просматриваемая страница.
Общая длина адреса (вместе с доменом), в идеале, не должна превышать 50 символов. Точнее говоря, длиннее она быть может, но тогда Яндекс покажет только часть URL`а (впрочем, он обязательно выберет кусочек с вхождением запроса).
Генерировать URL можно автоматически на основе нескольких первых слов заголовка страницы, переводя их в транслит с учётом предпочтений Google — не потому что это важный фактор при ранжировании, а от того, что дополнительное выделение жирным в сниппете привлечёт ещё немного бесценного внимания пользователя к вашему сайту на странице выдачи.
Согласны ли вы с тем, что описанные выше задачи больше подходят для разработчика, чем для маркетолога (хотя последний и будет пожинать плоды)? Если да, то, надеюсь, вам будет интересна и будущая статья, где хотелось бы обсудить альясы доменов с точки зрения SEO.
https://www.google.com/webmasters/tools/settings?hl=en&siteUrl=http://YOURSITE.RU/&tid=iup
Если вы будете использовать второй вариант - поисковики очень скоро самомтсоятельно смогут построить структуру вашего сайте а более адекватнее его индексировать.
А если вспомнить формулу BM25 и учесть, что по этой формуле считается коэффициент релевантности за счет вхождения запроса в URL - второй вариант будет хуже.
Есть ещё один момент, который нужно учитывать при выборе урла. По данным Google и Яндекс, ежегодно поисковики сталкиваются с 50-60% абсолютно новых поисковых запросов. Цифра огромная! И здесь, чем информативней у вас url, тем, теоретически, больше вероятность получить трафик по этим запросам.
Спасибо